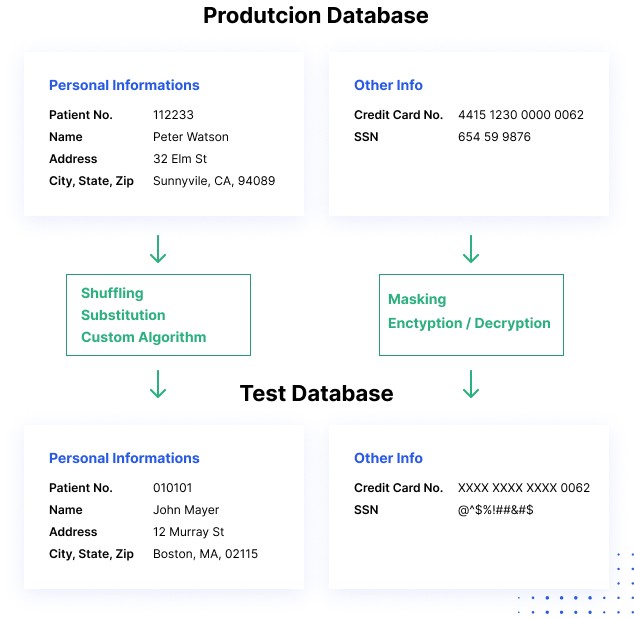
Data Masking
Data masking or data obfuscation is the process of modifying sensitive data in such a way that it is of no or little value to unauthorized intruders while still being usable by software or authorized personnel.
a way to create a fake but realistic version of our organizational data.
protect sensitive data while providing a functional alternative when real data is not needed.
The data Masking process changes the values of the data while using the same format.
the goal is to create a version that cannot be deciphered or reverse engineered
Several ways to alter data
- character shuffling
- word or character substitution
- encryption
Why is Data Masking Important?
Here are several reasons data masking is essential for many organizations:
- Data masking solves several critical threats – data loss, data ex-filtration, insider threats or account compromise, and insecure interfaces with third-party systems.
- Reduces data risks associated with cloud adoption.
- Makes data useless to an attacker, while maintaining many of its inherent functional properties.
- Allows sharing data with authorized users, such as testers and developers, without exposing production data.
- Can be used for data sanitization – normal file deletion still leaves traces of data in storage media, while sanitization replaces the old values with masked ones.
Data Masking Types:
- Static Data Masking
- Deterministic data masking
- On the fly data masking
- Dynamic data masking
Data Masking Techniques:
- Data Encryption
- Data Scrambling
- Nulling Out
- Value Variance
- Data Substitution
- Data Shuffling
- Pseudonymization
Data Masking Best Practices:
- Determine Project Scope
- Ensure Referential Integrity
- Secure the data masking Algorithms
Data Masking Tools:
DATAPROF:
Features:
- Consistent over multiple applications and databases.
- XML and CSV file support.
- Built-in synthetic data generators.
- HTML audit / GDPR reporting.
- Test data automation with REST API.
- Web Portal for easy provisioning.
Pros:
- High performance on large data sets.
- Free trial version available.
- Easy to install and use.
- Native support for all major relational databases.
Cons:
- English documentation only.
- Development of templates requires Windows.
- Execution of templates can be done on Windows or Linux.
IRI FieldShield
Features:
- Multi-source data profiling, discovery (search), and classification.
- Broad array of masking functions (including FPE) to de-identify and anonymize PII.
- Assures referential integrity across schema and multi-DB/file scenarios.
- Built-in re-ID risk scoring and audit trails for GDPR, HIPAA, PCI DSS, etc.
Pros:
- High performance, without the need for a central server.
- Simple metadata and multiple graphical job design options.
- Works with DB subsetting, synthesis, reorg, migration, and ETL jobs in Voracity, plus leading DB cloning, encryption key management, TDM portals, and SIEM environments.
- Fast support, and affordable (especially relative to IBM, Oracle, Informatica).
Cons:
- 1NF structured data support only; DarkShield needed for BLOBs, etc.
- Free IRI Workbench IDE is a thick client Eclipse UI (not web-based).
- DDM requires FieldShield API call, or premium proxy server option.
Accutive Data Discovery & Masking
Features:
- Data Discovery – Enables the efficient identification of sensitive data that need to meet regulatory compliance standards such as GDPR, PCI-DSS, HIPAA, GLBA, OSFI/PIPEDA, and FERPA.
- Mask Link Technology – Ability to consistently and repeatedly mask source data to the same value (i.e. Smith will always be masked to Jones) across multiple databases.
- Multiple Data Sources and Destinations – Data can be moved from any major source type to any major destination type such as Oracle, DB2, MySQL and SQLServer (e.g. data can be moved from a Flat File to an Oracle Database).
- API support – Include data masking in your data processing pipeline.
Pros:
- User-friendly, configurable interface.
- Cost-effective solution with transparent pricing models.
- Performs masking configurations rapidly with a built-in progress display.
Cons:
- Groovy scripting to customize application behavior requires some knowledge of programming.
- Not currently available in languages other than English, French, Spanish, and German.
IRI DarkShield
Features:
- Built-in data classification and simultaneous ability to search, mask, and report.
- Multiple search methods and masking functions, including fuzzy match and NER.
- Deletion function for GDPR (and similar) right to be forgotten laws.
- Integrates with SIEM/DOC environments and multiple logging conventions for audit.
Pros:
- High speed, multi-source, no need to mask in cloud or compromise control of data.
- Consistent ciphertext assures referential integrity in structured and unstructured data.
- Shares data classes, masking functions, engine, and job design GUI with FieldShield.
- Proven worldwide, but still affordable (or free with FieldShield in Voracity subscriptions).
Cons:
- Standalone and embedded image capabilities limited by OCR may need tweaking.
- API requires custom ‘glue code’ for cloud, DB, and big data sources.
- Price options may seem complex in a mixed data source and use case scenarios.
IRI CellShield EE
Features:
- Wide range of ergonomic PII searching and masking methods.
- Supports formulas and multi-byte character set.
- Leverages data classes, top masking functions, and search parameters of DarkShield GUI.
- Excel charts intelligently display discovered and masked data across multiple sheets.
Pros:
- High-performance masking of very large and/or multiple sheets at once.
- Consistent ciphertext assures referential integrity in sheets and other data sources.
- Search and mask audit column results, plus log exports to email, Splunk, and Datadog.
- Documented in-app and online. Easily upgradable from low-cost Personal Edition.
Cons:
- Only compatible with MS Excel 2007 or higher (not other sheet apps).
- Sharepoint and macro support are still in development.
- Free trial is only for Enterprise Edition (EE), not low-cost Personal Edition (PE).
Oracle Data Masking and Subsetting
Features:
- Discovers Complex Data and its relationships automatically.
- Wide Masking Plan Library and enhanced Application Models.
- Revolutions of complete data masking.
- Fast, Secure, and Assorted.
Pros:
- It proposes various customs for masking data.
- It supports non-oracle databases as well.
- It takes less time to run.
Cons:
- High-cost.
- Less secured for development and testing environments.
Delphix
Features:
- End-to-end data masking and creating reports for the same.
- Masking Combined with data virtualization to progress transport of the data.
- Easy in use as no training is required to mask data.
- It migrates data steadily across sites, on-premises, or in the cloud.
Pros:
- Easy and in-time regaining of records.
- Virtualization of databases.
- Data refreshing is fast.
Cons:
- High cost.
- SQL Server databases are slow and limited.
- Reliant on NFS old protocols.
Informatica Persistent Data Masking
Features:
- Supports Robust Data Masking.
- Creates and integrates the masking process from a single location.
- Features to handle a large volume of databases.
- It has wide connectivity and customized Application Support.
Pros:
- Decreases the risk of Data Break via a single audit trail.
- Advances the Quality of Development, Testing, and Training events.
- Easy deployment in the workstations.
Cons: Need to work more on UI.
Microsoft SQL Server Data Masking
Features:
- Simplification in designing and coding for applications by securing data.
- It doesn’t change or transform the stored data in the database.
- It permits the data manager to choose the level of complex data to expose with a lesser effect on the application.
Pros:
- End operators are prohibited from visualizing complex data.
- Generating a mask on a column field doesn’t avoid updates.
- Changes to applications are not essential to read data.
Cons:
- Data is fully accessible while querying tables as a privileged user.
- Masking can be unmasked via the CAST command by executing an ad-hoc query.
- Masking cannot be applied for the columns like Encrypted, FILESTREAM, or COLUMN_SET.
IBM InfoSphere Optim Data Privacy
Features:
- Mask private data on request.
- Decrease risk by locking data.
- Fasten data privacy application.
- A secure environment for application testing.
Pros:
- Easily abstracts data with no coding.
- Advanced-Data Masking Feature.
- Smart filtering abilities.
Cons:
- Need to work on UI.
- Complex architecture.
CA Test Data Manager
Features:
- Creates Synthetic test data for data testing.
- Creates future test scenarios and unexpected outcomes.
- Stores data for reuse.
- Creates virtual copies of test data.
Pros:
- Different filters and templates are present to mask data.
- No additional permission is required to access the production data.
- Very fast tools to mask data.
Cons:
- Works only on Windows.
- Complex User Interface.
- Automating everything is not easy.
Compuware Test Data Privacy
Features:
- Decreases the difficulty by codeless masking.
- Completes data normalization into and out of the masking process.
- Dynamic Privacy Rules with complex test data essentials such as account numbers, card numbers, etc.
- Allows to discover and mask data within a greater field.
Pros:
- Easy to use and is fast.
- Secures test data against breaks.
- Apply test data privacy to test data, so that it will be more secure.
Cons:
- Complex user Interface.
NextLabs Data Masking
Features:
- Helps in classifying and sorting data.
- Monitors data movement and its usage.
- It prevents access to precise data.
- Notifications on risky actions and irregularities.
Pros:
- Can be installed easily on each workstation.
- Evades data breaking.
- Data Safety across CAD, PLM, and email is good.
Cons:
- Software compatibility problems with PLM software.
- Execution is tough at times for the suppliers and vendors.
Hush-Hush
Features:
- Less time and Easy installation.
- Supple, Robustness and takes less time to create workflows.
- Easy and Robust Combination into SQL server, Biztalk, etc.
- Custom SSIS agenda to mask data.
Pros:
- Speed up development.
- No learning curves.
- Create data by just the “INSERT” command.
Cons:
- In startups the growth is fast but the progress slows down in developed industries.
- Limited control of data.
